
Learning with Label Proportions (LLP): Theory, Algorithm, and Applications
Summary
Useful information is sometimes released as statistics on the group level, making conventional instance-based learning methods non-applicable. For example, can we learn an object detection model, based on only image-level labels? Can we learn a user behavior or personality prediction model based on the coarse statistics over groups of different ethnicity, geo-social partitions?
We study the problem of learning with label proportions (LLP) in which the training data is provided in groups (or "bags"), and only the proportion of each class in each group is known. LLP has broad applications in political science, marketing, and computer vision. We proposed the pSVM algorithm, achieving the state-of-the-art results. We have also conducted theoretical analysis to understand the bounds and conditions affecting the performance of LLP. The study sheds lights on privacy protection when releasing group statistics. We applied LLP and the pSVM algorithm to solving various challenging problems in computer vision.
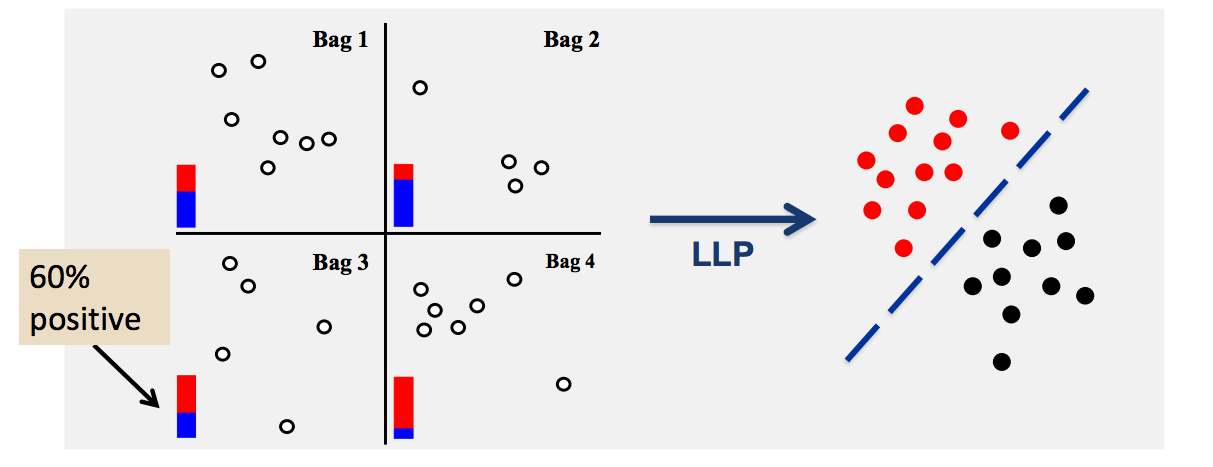
The pSVM Algorithm
We have proposed a method called proportion-SVM (pSVM, $\propto$SVM), which explicitly models the latent unknown instance labels together with the known group label proportions in a large-margin framework. Unlike the existing works, the proposed approach avoids making restrictive assumptions about the data. The proposed methods have shown very impressive performance compared to the former approaches. In addition, the resulted formulation is a flexible generalization of classic SVM - It naturally spans supervised, unsupervised, semi-supervised learning, learning with label noise, as well as learning with other group supervisions, such as comparable label proportions, and group-averaged attributes.
When and why LLP is possible?
As learning with label proportions is very different from conventional supervised learning, it is important to understand theoretically when and why such learning is possible. We have conducted analysis to answer the above question, and to understand how the parameters, such as group size and group proportions, affect the performance of the new learning paradigm. Specifically, we proposed a novel two-step analysis based on statistical learning theory. The first step provides a VC-bound on the generalization error of group proportions. It shows that the sample complexity for learning the group proportion is only mildly sensitive to the group size. The second step demonstrates that under certain conditions, such as "the instances are conditionally independent given group", a good group proportion predictor guarantees a good instance label predictor. The proposed analysis holds for any algorithms. The study provides not only theoretical support on the feasibility of learning with label proportions, but also guidance on designing new algorithms, and protecting privacies when releasing group statistics.
Applications (in Computer Vision)
The pSVM algorithm, and its variants, are being applied to solving various problems in computer vision:
1. Attribute modeling based on category-attribute proportions (Bags: image categories | Instances: images)

2. Localizing event shots given only video event labels (Bags: videos | Instances: "shots")

3. Discovering discriminative patches given only image-level scene labels (Bags: images | Instances: image patches)

Papers
Felix X. Yu; Dong Liu; Sanjiv Kumar; Tony Jebara; Shih-Fu Chang. $\propto$SVM for learning with label proportions ICML 2013 oral (full-length) (acceptance rate 12%) [PDF] [Supp] [arXiv] [GitHub] [Slides] [Project]
Felix X. Yu; Sanjiv Kumar; Tony Jebara; Shih-Fu Chang. On learning from label proportions [arXiv]
Kuan-Ting Lai; Felix X. Yu; Ming-Syan Chen; Shih-Fu Chang. Video event detection by inferring temporal instance labels CVPR 2014 oral (acceptance rate 5.75%) [PDF]
Tao Chen; Felix X. Yu; Jiawei Chen; Yin Cui; Yan-Ying Chen; Shih-Fu Chang. Object-based visual sentiment concept analysis and application ACM Multimedia 2014 oral (acceptance rate 20%) [PDF]
Felix X. Yu; Liangliang Cao; Michele Merler; Noel Codella; Tao Chen; John R. Smith; Shih-Fu Chang Modeling Attributes from Category-Attribute Proportions ACM Multimedia 2014 (Short paper, acceptance rate 30%) [PDF]