
Weak Attribute for Large-Scale Image Retrieval
Summary
Attribute-based query offers an intuitive way of image retrieval, in which users can describe the intended search targets with understandable attributes. In this paper, we develop a general and powerful framework to solve this problem by leveraging a large pool of weak attributes comprised of automatic classifier scores or other mid-level representations that can be easily acquired with little or no human labor.
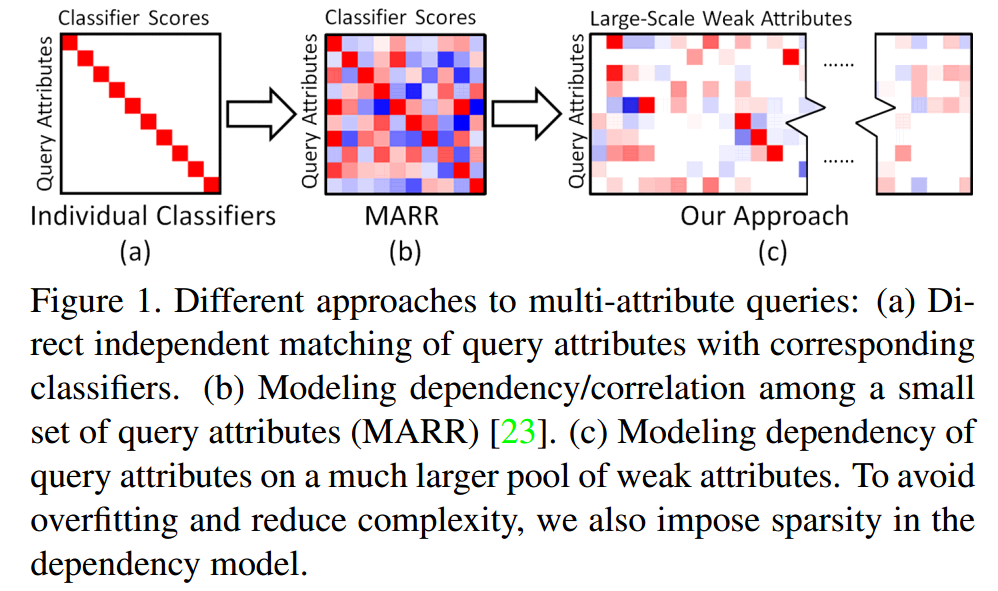
We extend the existing retrieval model of modeling dependency within query attributes to modeling dependency of query attributes on a large pool of weak attributes, which is more expressive and scalable. To efficiently learn such a large dependency model without overfitting, we further propose a semi-supervised graphical model to map each multi-attribute query to a subset of weak attributes. Through extensive experiments over several attribute benchmarks, we demonstrate consistent and significant performance improvements over the state-of-the-art techniques.
In addition, we compile the largest multi-attribute image retrieval dateset to date, including 126 fully labeled query attributes and 6,000 weak attributes of 0.26 million images.
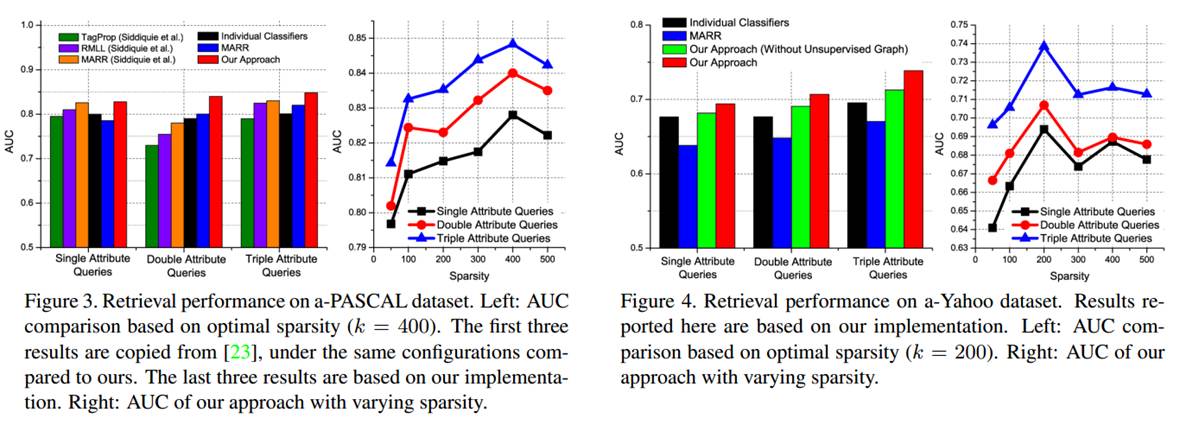
Performance evaluation on a-PASCAL and a-Yahoo
The a-TRECVID dataset is available here
Matlab code for the proposed semi-supervised graphical model
Download ReadmePlease direct any questions to Felix X. Yu (yuxinnan (at) ee.columbia.edu)
Publications
Felix X. Yu; Rongrong Ji; Ming-Hen Tsai; Guangnan Ye; Shih-Fu Chang. Weak attributes for large-scale image retrieval CVPR 2012 [PDF]
Felix X. Yu; Rongrong Ji; Ming-Hen Tsai; Guangnan Ye; Shih-Fu Chang. Experiments of image retrieval using weak attributes Technical Report # CUCS 005-12 [PDF]